

AI Enablement
Ultimate Guide to AI Deployment Frameworks
87% of AI projects fail to reach production. Why? Deployment challenges. An AI deployment framework can solve this by standardizing processes like data handling, model training, and monitoring, ensuring AI systems are production-ready and scalable.
Here’s what you’ll learn:
Why frameworks matter: They improve security, compliance, and efficiency.
Common challenges: Model drift, infrastructure mismatches, and uncontrolled costs.
Core components: Infrastructure, model management, and compliance.
Step-by-step deployment: From prerequisites to monitoring.
Rebel Force’s approach: A structured method to fix bottlenecks and boost ROI.
These frameworks turn AI prototypes into reliable tools, saving costs and improving performance. Ready to fix your AI deployment process? Let’s dive in.
Step-by-Step Guide to Implementing AI Solutions: From Planning to Deployment
Core Components of an AI Deployment Framework
Creating a production-ready AI system isn’t just about building a smart model - it requires a solid foundation of scalable infrastructure, effective model management, and seamless integration with compliance. These three elements work together to transform experimental AI prototypes into dependable enterprise tools. Without them, even the most advanced AI models can get stuck in development limbo. Together, they tackle the operational challenges that often derail AI projects, ensuring a smooth transition from prototype to production.
Infrastructure and Scalability
At the heart of any AI system is its ability to meet real-world demands. This starts with GPU-enabled compute that supports high-performance networking (like RDMA and low-latency fabrics) and virtualization platforms designed for parallel workloads. The data layer must also deliver high-throughput parallel access, combining tiered storage to balance performance with cost efficiency. Container orchestration tools like Kubernetes handle scheduling, scaling, and resource allocation across cloud, on-premises, and edge environments.
Here’s why this matters: a 20% boost in GPU utilization can save enterprises between $24,000 and $50,000 annually per GPU. For example, smaller, fine-tuned models like Llama 3 8B can run 13 times faster and cut costs by up to 33 times compared to GPT-4, all while outperforming it on 85% of domain-specific tasks. The trick is to align your deployment model with your workload. For instance:
Cloud stacks: Best for elastic scaling during large-scale training.
Edge stacks: Ideal for low-latency real-time inference.
Hybrid stacks: Balance flexibility with control over data sovereignty.
While scalable infrastructure ensures your AI can handle real-world pressure, robust model management keeps it performing at its best over time.
Model Management and Optimization
To keep AI systems running smoothly, structured operational processes are key. MLOps frameworks help maintain consistency and reduce errors during deployment cycles. Techniques like pruning and quantization shrink model sizes and speed up inference, making operations more cost-efficient. Continuous monitoring tracks system health (like CPU/GPU usage) and model performance (accuracy, precision, latency), catching issues like model drift before they cause problems.
Proactive monitoring can lead to a 65% performance improvement. Automated retraining mechanisms kick in when performance drops, keeping models effective over time. Version control for models and prompts allows teams to quickly revert to a previous state if a new deployment doesn’t perform as expected. Shadow deployment, where new models run alongside live systems, provides a safe way to test updates without risking user experience.
When paired with strong infrastructure, smart model management lays the groundwork for success. But without seamless integration and compliance, even the best systems can falter.
Integration and Compliance
For AI to thrive in enterprise settings, it must integrate smoothly with existing systems and comply with strict regulations. Frameworks need to align with laws like the EU AI Act, GDPR, CCPA, HIPAA, and DORA. Security measures such as Zero-Trust architectures, Role-Based Access Control (RBAC), and Just-in-Time approvals for high-risk actions are essential. Features like immutable audit logs, model cards detailing intended use, and version control enhance accountability.
The global AI governance market is expected to hit $1,418.3 million by 2030, growing at a CAGR of 35.7%. Integrating AI with older systems often involves middleware adapters or API modernization. In high-stakes industries like healthcare and finance, Human-in-the-Loop systems are critical for reviewing AI decisions before they’re implemented. Compliance isn’t just about following rules - it’s about maintaining trust and ensuring operational discipline.
"Deployment architecture is not a technical afterthought. It's a strategic decision that affects your data residency compliance, your IT team's workload, and how much visibility you have into what's happening with your data".
Bernard Aceituno, Co-Founder and President of StackAI
Step-by-Step Guide to AI Deployment
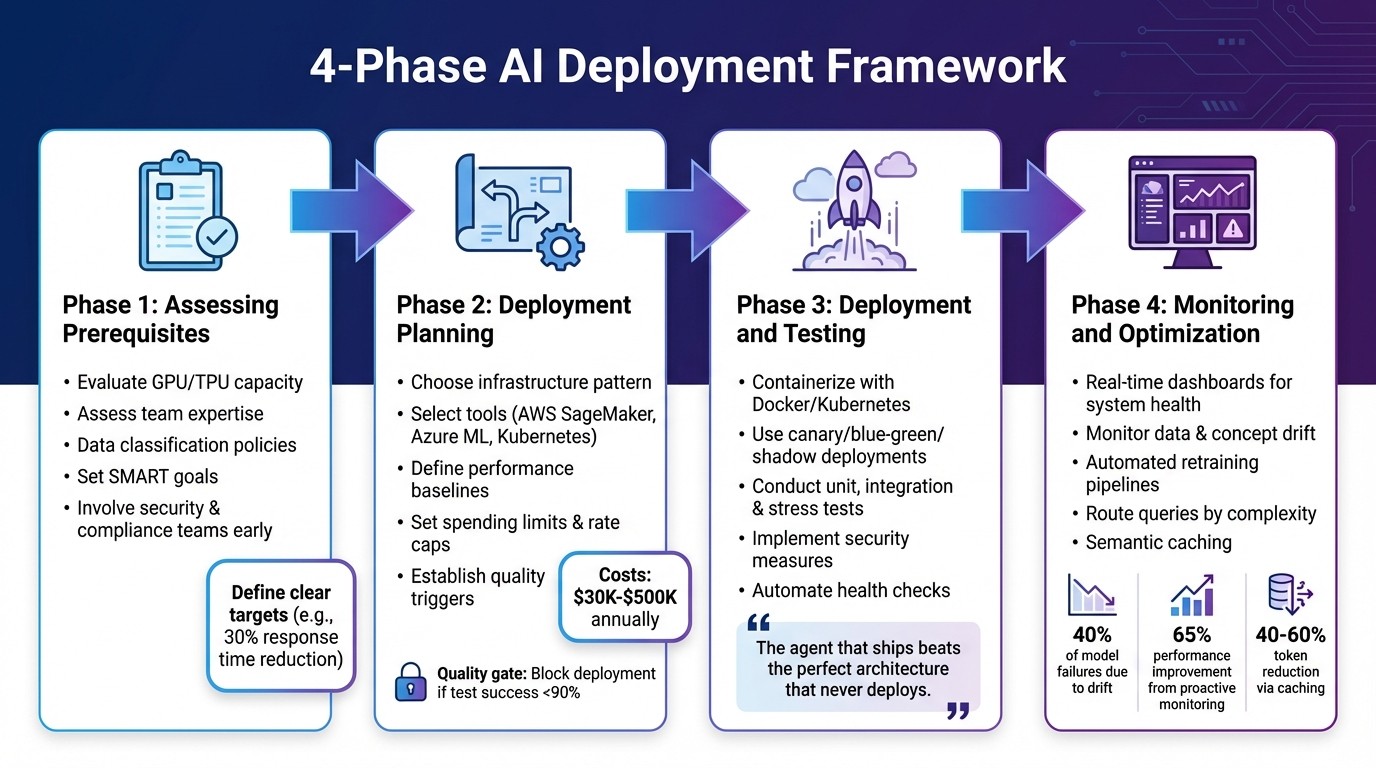
4-Phase AI Deployment Framework: From Assessment to Optimization
Deploying an AI model into production requires careful planning, execution, and ongoing monitoring. A structured approach ensures a smoother transition and long-term success. Here's a breakdown of the four key phases involved.
Phase 1: Assessing Prerequisites
Before diving into development, it's crucial to evaluate your starting point. Begin by checking your computational resources - do you have enough GPU/TPU capacity, memory, and storage? Next, assess your team's expertise in areas like model architecture, system integration, and MLOps.
Data readiness is another critical factor. Create data classification policies to separate sensitive information (such as PII or PHI) from non-sensitive data. This step helps determine whether you need a hybrid or on-premise setup (common in healthcare for HIPAA compliance) or if a VPC-isolated cloud environment will suffice for less regulated cases.
Prepare for potential errors by setting up retry logic with exponential backoff and circuit breakers to handle API failures. Establish SMART goals - specific, measurable, achievable, relevant, and time-bound. For instance, instead of vaguely aiming to "improve efficiency", set a clear target like reducing response time by 30% within six months.
Map out your current workflows to identify bottlenecks, and involve security, legal, and compliance teams early to define data boundaries and access controls. With these prerequisites in place, you're ready to move on to planning your deployment.
Phase 2: Deployment Planning
A well-defined roadmap is the backbone of successful deployment. Start by choosing an infrastructure pattern that aligns with your compliance and security needs. Costs typically range from $30,000 to $500,000 annually, depending on the setup. For example, air-gapped systems are ideal for defense applications, VPC-isolated cloud environments suit general enterprise needs, and hybrid cloud setups provide a balance between data residency and flexibility.
Select the right tools for the job. Managed platforms like AWS SageMaker or Azure ML offer scalability and convenience, while open-source options like vLLM and Kubernetes provide greater control. Define performance baselines for latency (p50, p95, p99), throughput, and token usage costs. To avoid budget overruns, set hard spending limits, per-user rate caps, and automated alerts.
Establish a "no-go" trigger to maintain quality. For instance, block deployment if your test set success rate drops below 90%. With a clear plan in place, you're ready to move to the next phase: controlled deployment and testing.
Phase 3: Deployment and Testing
Standardization is key here. Containerize your models using Docker and Kubernetes to create reproducible environments that isolate dependencies. For a low-risk rollout, consider strategies like:
Canary deployments: Gradually divert traffic to the new model.
Blue-green deployments: Allow for zero-downtime transitions.
Shadow mode: Run the new model in the background to compare outputs without impacting users.
Testing is non-negotiable. Conduct unit tests, integration tests (with mocked responses), and stress tests using synthetic datasets. Strengthen security by implementing measures like prompt injection detection, input validation, and output filtering to prevent data leaks. Automate health checks to ensure containers and dependencies are functioning properly before routing traffic. Finally, version control your prompts for quick rollbacks if needed.
"The agent that ships beats the perfect architecture that never deploys." - Vinod Chugani, Machine Learning Mastery
Phase 4: Monitoring and Optimization
Deployment doesn't end once the model is live - it’s an ongoing process. Use real-time dashboards to monitor system health (e.g., CPU/GPU usage) and model behavior (like prediction distributions and confidence scores). Watch for data drift and concept drift, which account for 40% of all model failures in production.
When performance declines, automated retraining pipelines should activate to keep the model effective. Pair this with human-in-the-loop reviews for failed interactions. To cut costs, route simple queries to smaller models and reserve advanced models for more complex tasks. Semantic caching can also reduce token usage by 40–60%.
Proactive monitoring isn't just a good practice - it can lead to a 65% boost in system performance. This makes it one of the most impactful activities in the deployment lifecycle.
Applying Rebel Force's Enablement Process
Rebel Force's enablement process is designed to tackle the internal challenges that can derail AI deployment. While technical execution is a key part of the equation, the real challenge often lies in addressing organizational bottlenecks. Rebel Force takes a bottleneck-first approach, focusing on identifying and resolving the specific constraints that prevent AI initiatives from delivering results. Instead of diving straight into tools or strategies, they begin by diagnosing the root cause of inefficiencies.
Diagnose, Design, Execute, Validate
This enablement process consists of four phases that align with the AI deployment lifecycle, but with a unique emphasis on restoring measurable flow. Here's how it works:
Diagnose: The process kicks off with a thorough analysis of your data, team dynamics, and workflows to uncover where implementation is stalling. This deep dive identifies hidden constraints within the organization.
Design: Once the bottleneck is identified, the team creates an Enablement Blueprint aimed at addressing that specific issue.
Execute: Rebel Flow Units - specialized cross-functional teams - are deployed. These teams include roles such as an Enablement Lead, AI/Data Specialist, Process Designer, Creative Technologist, and Performance Analyst, all working closely with your internal teams.
Validate: Finally, they measure the return on investment (ROI) and document lessons learned to guide future initiatives. Rebel Force reports an average ROI of 70% for projects completed through this process, with over 220 successful implementations to date.
"Every engagement starts with diagnosis, not design. We identify the core constraint - the point where flow breaks - before touching tools, teams, or strategy." - Rebel Force
This process doesn't just solve immediate problems; it ensures your teams can eventually manage the enablement system independently. This autonomy supports long-term scalability without creating ongoing reliance on external support.
Enablement Sprints vs. Enablement Programs
Rebel Force offers two tailored models to fit different organizational needs: Enablement Sprints and Enablement Programs.
Enablement Sprints: These are 12-week projects aimed at quickly resolving a dominant constraint. Sprints focus on delivering fast, measurable results and are tied to a specific ROI target. They're ideal for addressing urgent, high-impact challenges.
Enablement Programs: Spanning 12 months, these programs focus on gradual transformation, making them better suited for organizations seeking widespread, sustainable change. The same structured four-phase process is applied, but at a controlled pace.
Plan Name | Timeline | Key Features | Ideal Use Case |
|---|---|---|---|
Enablement Sprints | 12 weeks | Quick fixes with measurable ROI | Addressing specific, pressing bottlenecks |
Enablement Programs | 12 months | Gradual, scalable organizational transformation | Long-term, comprehensive business changes |
Both models rely on the same core methodology and team structure. The main difference lies in the pace of implementation - Sprints are designed for rapid results, while Programs allow for more gradual, comprehensive transformation. For particularly complex projects, timelines can be extended to 24, 36, or even 48 weeks.
Conclusion: Key Takeaways for AI Deployment Success
Looking at the framework components and Rebel Force's approach, a few critical lessons stand out. For AI deployment to succeed, it requires a framework that is not only scalable but also adaptable to your organization's evolving needs. This framework should tackle specific challenges directly, aligning AI initiatives with clear business goals. Companies that adopt such frameworks often see tangible benefits, like a 30% boost in operational efficiency and a 25% drop in compliance-related issues.
However, the road to success isn't without its hurdles. For instance, 95% of generative AI pilots fail to deliver meaningful financial results, and only 29% of executives feel confident in measuring AI ROI. This highlights the importance of focusing on the primary bottlenecks in your workflows to drive impactful outcomes.
"Production AI deployment is an ongoing operational practice, not a one-time event." - AI Agents Plus Editorial
Start small - think constrained workflows or an MVP - and build from there. Use strategies like version-controlling your prompts and rolling out updates gradually, such as through canary deployments. Real-time monitoring, strict token usage limits, and human oversight at critical decision points are non-negotiable, especially for high-stakes applications. These measures help manage risks and keep costs in check.
Final Thoughts
The AI deployment process, as discussed earlier, is a journey that requires careful planning and execution. The global AI market is on track to hit $900 billion by 2026, and by 2028, over 33% of enterprise applications are expected to integrate AI agents. Thriving in this fast-changing environment calls for more than just technical know-how. It demands a structured approach to pinpointing constraints, crafting targeted solutions, and validating success through measurable results.
Whether your organization opts for a quick 12-week sprint to address pressing issues or a longer 12-month program for a complete overhaul, the focus should always remain on improving workflow efficiency. The companies that succeed will be those that approach AI strategically, scale their efforts thoughtfully, and ensure human oversight remains central throughout the deployment lifecycle.
FAQs
What’s the minimum setup needed to deploy AI in production?
To deploy AI in a production setting, you’ll need a containerized environment - tools like Docker or Kubernetes are great for ensuring scalability and reliability. It’s also crucial to implement security measures, such as access control and state management, to minimise risks and system failures. When it comes to deployment methods, your choice - whether cloud APIs, serverless options, or container-based systems - should align with your priorities for latency, cost, and scalability. A solid plan and dependable infrastructure are the backbone of a successful deployment.
How do I prevent model drift after launch?
Keeping a machine learning model performing well over time requires continuous monitoring and maintenance. Here’s how to stay ahead of model drift:
Track performance metrics regularly: Compare the model's current results to its original baseline. This helps you spot any decline in accuracy or effectiveness.
Retrain with fresh data: Incorporate new, high-quality data into the model periodically. This ensures it stays relevant and aligned with real-world changes.
Set thresholds for performance: Use monitoring tools to define acceptable performance levels. If the model's metrics fall below these thresholds, you’ll know it’s time to intervene.
Conduct pre-deployment checks: Systematic evaluations before launching the model help ensure it’s in good shape and ready to deliver reliable results.
By staying proactive with these steps, you can catch and address any issues before they impact the model's overall reliability.
How can Rebel Force help improve AI deployment ROI?
Rebel Force boosts the return on investment (ROI) from AI deployments by fine-tuning business operations with customised, data-focused enablement systems. Their approach involves identifying bottlenecks, creating tailored strategies, implementing solutions, and measuring results to ensure clear ROI. By concentrating on AI integration, process improvement, and streamlining organizational workflows, Rebel Force helps businesses achieve scalable results that align with their goals - enhancing efficiency, cutting costs, and driving meaningful business outcomes.