

Data Strategy
AI-Driven ETL: Blueprint for Data Pipeline Success
AI-powered ETL systems are transforming how businesses handle data pipelines by automating tasks and fixing common issues like schema changes, unstructured data, and quality errors. Traditional ETL processes rely heavily on manual updates, but AI-enabled systems can adapt to changes, reduce errors, and save time.
Key Takeaways:
Automation: AI minimizes manual intervention, cutting data processing times by up to 50%.
Self-Healing Pipelines: Automatically adjusts to schema changes and detects anomalies.
Low-Code Tools: Enables non-technical users to create workflows, making data management more accessible.
Cost Savings: Companies save thousands of hours and report up to a 355% ROI over three years.
Scalability: Handles growing data volumes and complexity with real-time performance optimization.
By following a structured process - Diagnose, Design, Execute, Validate - AI-driven ETL ensures smoother, faster, and more reliable data pipelines. Whether tackling one bottleneck at a time or modernizing entire systems, these methods deliver measurable results.
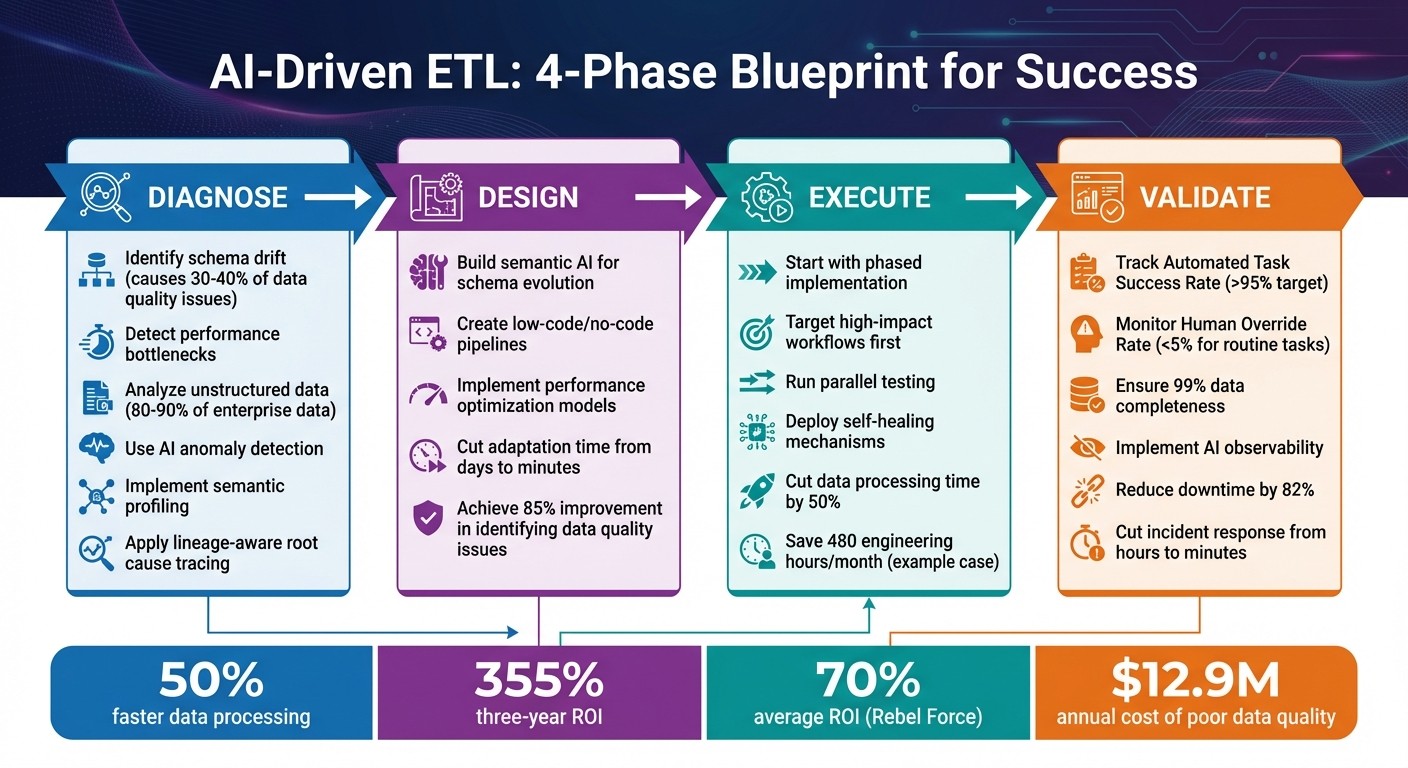
AI-Driven ETL Four-Phase Implementation Framework
I built this complete ETL data pipeline with an AI Agent!
Diagnosing Pipeline Constraints
Before diving into AI-driven solutions, it's crucial to pinpoint what's going wrong in your current data pipelines. For instance, schema drift is a major culprit, responsible for 30% to 40% of data quality issues in mature organizations. Imagine a source system suddenly switching a date format from MM/DD/YYYY to YYYY-MM-DD - traditional pipelines often break instantly. Engineers then burn days manually updating transformation logic just to get things running again. Identifying these weak points is key before deploying AI solutions.
Performance bottlenecks add another layer of complexity. Rigid batch processing introduces delays, creating blind spots during critical operations like fraud detection or dynamic pricing. At the same time, unstructured data - which makes up 80% to 90% of enterprise information - often remains unused. Traditional ETL tools struggle with PDFs, images, or free-text data, leaving teams stuck with manual data entry processes that simply can't scale.
Common ETL Failures and Their Impact
These pipeline constraints often show up as failures that undermine data integrity and analytics. One of the trickiest issues is semantic drift - when data passes structural checks but its meaning changes. For example, a currency field might switch from dollars to cents without anyone noticing. Without AI tools to monitor semantic consistency, these shifts can go undetected until business reports reveal strange anomalies.
"Schema evolution is the silent killer of production AI pipelines... six hours later, your feature store is serving nulls to a model that was never trained on nulls." – Nitil, Data & GenAI Architect
Legacy system compatibility only makes things harder. When systems introduce semi-structured formats like JSON or XML, older pipelines that rely on fixed schemas and predefined mappings often fail. Inconsistent formats - like one system using "03/24/2026" for a date while another uses "March 24, 2026" - lead to duplicate records or missing values. This can cause "silent feature corruption", where AI models produce flawed results without triggering errors. AI diagnostic tools can uncover these inconsistencies, ensuring smoother integration.
AI Tools for Constraint Diagnosis
AI offers powerful tools to tackle these pipeline issues, starting with intelligent anomaly detection. These systems establish baselines for data metrics like volume, freshness, and value distributions. When something unusual happens - like null values spiking from 2% to 15% or unexpected data surges during off-peak hours - AI triggers alerts immediately. This shifts teams from reacting to problems after the fact to addressing them proactively.
Semantic profiling takes this a step further by using Natural Language Processing to understand the meaning behind data fields. For example, it can recognize that "cust_id" and "client_identifier" both refer to the same entity, even if different systems use different labels. This is especially helpful when dealing with legacy systems or mapping data across disparate sources.
Another game-changer is lineage-aware root cause tracing, which tracks data flow across jobs to pinpoint where errors originate. Instead of spending hours combing through logs, AI can identify the exact transformation step where data quality degraded and show which reports, dashboards, or models are affected. This precision cuts recovery time from hours to seconds. These AI-driven diagnostics set the stage for building stronger, more reliable transformation strategies.
Designing AI-Enabled Transformations
Once you've pinpointed the weak spots in your data pipelines, the next step is to redesign the transformation processes to handle complexity automatically. This shift can cut adaptation times from days to mere minutes. By doing so, you create pipelines that adapt to the ever-changing nature of modern data sources without requiring constant manual intervention. Leveraging these diagnostics, AI-enabled transformations ensure your pipelines stay aligned with evolving data environments.
This approach moves away from rigid, rule-based systems to smarter methods that grasp context and meaning. For instance, traditional ETL processes often demand engineers to map variations like "cust_id", "customer_identifier", and "client_ID" manually. In contrast, AI-enabled transformations use semantic understanding to recognize these as the same concept automatically.
Semantic AI for Schema Evolution
Semantic AI takes advantage of Natural Language Processing (NLP) to analyze actual data content, values, and patterns - not just the metadata. For example, if a source system changes a field name from "order_date" to "purchase_timestamp", semantic AI understands that the business concept remains unchanged and updates the mapping automatically.
This technology compares schemas between old and new versions to maintain data integrity. For instance, if a vendor switches from storing prices in dollars to cents (e.g., $49.99 becomes 4999), semantic AI detects this shift by analyzing value patterns before the data corrupts your warehouse.
Predictive models also monitor for structural changes in source systems, flagging potential schema issues before they occur. Additionally, AI can uncover table relationships and field meanings in undocumented legacy systems. Companies using these capabilities report an 85% improvement in identifying data quality issues, while poor data quality continues to cost enterprises an average of $12.9 million annually.
Low-Code and No-Code Pipelines
While semantic AI simplifies technical mapping, low-code platforms make pipeline creation accessible to a broader audience. AI empowers business analysts and other non-technical users to design data workflows without needing to write code. Many platforms now offer extensive libraries of pre-built transformations. For example, Integrate.io provides over 220 pre-built options, reducing the need for custom coding in common operations. Natural language interfaces further enhance usability by letting users describe transformations in plain English, which AI then converts into optimized logic.
"The drag-and-drop pipeline builder eliminates the coding expertise barrier that excludes 75% of potential pipeline creators." – Integrate.io
This democratization of pipeline creation reduces development time from weeks to just hours. Organizations can also cut data processing times by up to 50% compared to traditional tools. AI-ETL platforms have shown to deliver a 355% three-year ROI by speeding up deployment and lowering development costs.
However, these advancements require robust governance to ensure transparency in AI-driven mappings. When AI automates transformations, maintaining traceability becomes critical. Teams need tools that explain why specific mappings were made. Additionally, automated pipelines must be carefully managed to avoid bypassing data privacy controls. Choosing platforms with "Explainable AI" features and implementing a hybrid governance model - where some tasks remain under human oversight - are vital steps.
Performance Optimization Models
Optimizing transformations in real time further boosts pipeline efficiency and resilience. AI-driven performance models analyze historical data on execution times, volumes, and resource use to predict future demands. This allows systems to scale compute capacity ahead of peak usage. Dynamic workload balancing redistributes resources across multi-cloud setups like AWS, GCP, and Azure to maintain performance during traffic spikes.
Machine learning fine-tunes configurations such as batch sizes, parallelization, and memory allocation, while also scheduling jobs based on real-time demands, resource costs, and downstream dependencies. These techniques can increase throughput by 40% and cut latency by 30%. On top of that, organizations save an average of $152,000 annually on infrastructure costs.
Failure prediction models analyze past runs to identify potential bottlenecks or failures in Directed Acyclic Graphs (DAGs) before they disrupt production. Structuring pipelines with a modular architecture - separating ingestion, transformation, and serving layers - ensures that individual components can scale independently without affecting the entire system. For real-time efficiency, embedding machine learning models into streaming frameworks like Apache Spark Structured Streaming allows the system to respond instantly to volume spikes.
Executing AI-Driven ETL with Automation
Once you've mapped out AI-enabled transformations, the next step is putting them into action. But instead of diving straight into full automation, it's smarter to ease into production. A gradual rollout minimizes risks, reduces resistance, and lets you address challenges as they arise. Plus, it builds trust in the process by delivering clear results at every step.
The key to success? Start by identifying the biggest bottleneck in your data flow - the point where things tend to break down. For example, you might find that a high-frequency workflow is eating up engineering resources due to constant schema changes. Focus your initial automation efforts on processes that run daily, are prone to errors, directly impact revenue, or are resource-heavy. This step-by-step approach ensures you're building on a solid foundation of diagnostics and thoughtful design.
Phased Implementation Strategy
To execute effectively, follow a structured plan: identify constraints, create an implementation blueprint, connect and configure your data sources, test thoroughly, and then deploy with active monitoring. AI tools can help streamline this process by auto-discovering tables and suggesting mappings, which speeds up setup and allows for easy visual adjustments.
Before fully committing to AI-driven pipelines, test them alongside traditional systems to ensure they meet business requirements. Running both in parallel helps you catch and address any discrepancies between AI outputs and manual processes. Start with non-critical workflows to test the system's capabilities, such as self-healing and anomaly detection, before moving on to high-stakes processes.
The benefits of this approach are clear. For example, a major retailer reported saving 480 engineering hours each month by using AI-ETL with no-code automation. By prioritizing high-impact workflows - those prone to errors or demanding significant resources - you can achieve similar results. Once the system proves its value, you can scale it to more data sources and use cases. Organizations that follow this phased strategy have reported cutting data processing times by up to 50% compared to older methods.
This phased method sets the stage for tailored solutions like those offered by Rebel Force, which supports both quick wins and long-term transformation.
Rebel Force Enablement Sprints and Programs
Rebel Force offers two structured engagement models designed to turn diagnosed constraints into measurable outcomes. Both models follow the same methodology - Diagnose, Design, Execute, Validate - but differ in their intensity and timeline.
Enablement Sprints are 12-week, high-intensity projects aimed at quickly removing a major bottleneck. These sprints are ideal for situations where immediate results are needed, such as fixing a failing pipeline or unblocking a key analytics process. Each sprint is supported by a dedicated team, including an Enablement Lead, AI/Data Specialist, Process Designer, Creative Technologist, and Performance Analyst. The pricing is fixed per sprint, with a clear ROI target. On average, Rebel Force reports a 70% ROI across their engagements.
Enablement Programs, on the other hand, are designed for organizations seeking long-term transformation. Spanning 12 months, these programs focus on steady, sustainable improvements across multiple data pipelines. While the methodology remains the same, the pace shifts from rapid execution to strategic, ongoing development. This approach is better suited for enterprises looking to modernize their data infrastructure without disrupting daily operations.
Feature | Enablement Sprints | Enablement Programs |
|---|---|---|
Duration | 12 weeks | 12 months |
Primary Goal | Quickly eliminate a major bottleneck | Gradual, organization-wide transformation |
Tempo | High-intensity, fast results | Strategic, steady progress |
Pricing Model | Fixed price per sprint with ROI targets | Annual program cost |
Best For | Immediate fixes and proofs of concept | Comprehensive pipeline modernization |
The fixed-price model eliminates the uncertainty of hourly billing and ensures that both parties are focused on delivering measurable outcomes. These programs also help internal teams build the skills they need to maintain AI-ETL systems independently.
Once deployed, automated orchestration takes over, monitoring compute resources, pricing, and dependencies. Self-healing mechanisms quickly detect and resolve failures, turning AI-driven ETL into a strategic asset rather than just a technical upgrade.
Validating and Optimizing Outcomes
Once you've deployed an AI-driven ETL solution, the work doesn’t stop there. Validation and ongoing optimization are what ensure your pipeline continues to deliver value. Without clear performance metrics, you’re essentially flying blind. Modern AI observability tools can help by giving you detailed insights, helping you track performance, pinpoint issues early, and make continuous improvements.
Establishing Metrics for Success
Defining success is the first step. For example, the Automated Task Success Rate (ATSR) measures how often your ETL processes complete without needing human intervention. Ideally, you should aim for an ATSR of over 95% for low-risk workflows and 99.9% for high-risk ones. Another key metric is the Human Override Rate (HOR) - if human intervention exceeds 5% for routine tasks or 0.5% for critical processes, it’s a sign your models may need adjustment.
Data quality metrics are just as crucial. Critical fields should maintain over 99% completeness, with real-time data freshness latency under five minutes. Error rates should stay below 0.05%. For model health, a Population Stability Index (PSI) below 0.1 indicates stability, while anything above 0.25 signals the need for immediate attention.
To stay on top of these metrics, adopt a layered approach to monitoring - real-time, daily, and monthly checks. This strategy helps you catch problems early without being overwhelmed by constant alerts. These benchmarks lay the groundwork for advanced observability that can refine your ETL processes even further.
Continuous Improvement Through AI Observability
Traditional ETL monitoring mostly tracks job statuses, but AI observability goes much deeper. It provides insights into data quality, schema changes, and lineage tracking. Automated agents can even diagnose failures and trigger self-healing actions. Considering that data teams spend about 40% of their time troubleshooting pipeline issues, these advanced tools can save a lot of effort.
Self-healing pipelines take reliability to the next level. They handle tasks like intelligent retries, dynamic resource scaling (e.g., adding Spark executors), and automated rollbacks for failed loads. These capabilities can reduce downtime by 82% and deliver 99.999% availability.
The benefits don’t stop there. Comprehensive observability can reduce SLA breaches by 96% and cut incident response times from hours to just minutes. AI-powered tools also enable 90% faster issue detection and reduce manual troubleshooting efforts by 75%. When you consider that downtime from failed ETL jobs can cost up to $5,000 per minute, these improvements directly boost operational efficiency.
To get the most out of observability, standardize validation rules using reusable templates for checks like null values and referential integrity. Use lineage-based root cause analysis to trace data issues back to their source. For high-risk tasks, such as those involving schema changes or financial data, include human-in-the-loop safeguards to ensure processes are explicitly approved before execution.
Case Studies: Measured Impact
Real-world examples show how these practices translate into measurable results. Take Rivulet IQ, a small 12-person agency. In January 2026, they implemented an AI-driven workflow for tasks like reporting and triage, following a structured process: Capture → Normalize → Enrich → Draft → Verify. The result? They saved 40 hours per week on reporting and ticketing.
"If you want AI to save time, you have to stop asking it to guess what your agency meant." – Rivulet IQ
In another example, Belgium's Fédération Wallonie-Bruxelles, serving 4.5 million citizens, revamped its legacy data systems under the leadership of Martin Erpicum in February 2026. By adopting an asset-centric data platform, they doubled pipeline delivery speed and eliminated manual Excel-based processes that used to take months. Erpicum emphasized, "No vendor lock-in means that 90% of our code can be re-used anywhere".
Similarly, HIVED, a UK-based company, replaced traditional cron-based workflows with an AI-ready orchestration platform in November 2025. They achieved 99.9% pipeline reliability and zero major data incidents over three years. Meanwhile, German FinTech company smava migrated over 1,000 dbt models to an automated orchestration platform, completing the transition without any downtime and cutting developer onboarding time from weeks to just 15 minutes.
These examples highlight how a validation-focused approach can drive consistent results. Rebel Force, for instance, applies these principles across both short-term Enablement Sprints and longer-term Programs, ensuring every AI-driven ETL solution delivers measurable outcomes. Their fixed-price model aligns goals with results, making validation a central part of every project.
Conclusion
AI-driven ETL transforms outdated, manual workflows into flexible, self-adjusting systems. The process follows four key steps: identifying constraints, designing flexible transformations, automating processes to reduce repetitive tasks by up to 60%, and validating results with clear metrics.
Companies using AI-powered ETL platforms have seen data processing times cut by up to 50% and achieved a 355% three-year ROI. Considering poor data quality costs the U.S. economy roughly $3 trillion annually, these advancements directly enhance operational efficiency and performance.
Rebel Force's four-phase framework - Diagnose, Design, Execute, Validate - illustrates this transformation effectively, delivering an average 70% ROI on AI investments. Their approach, whether through targeted 12-week Enablement Sprints or broader 12-month Programs, ensures that AI-driven ETL solutions go beyond technical fixes to deliver measurable results.
"We don't sell packages. We fix systems... We identify the core constraint - the point where flow breaks - before touching tools, teams, or strategy." – Rebel Force
This structured methodology sets the stage for lasting competitive advantages. With data volumes surging and predictions that 75% of enterprise data will be processed at the edge by 2026, transitioning from batch-based to real-time ETL is no longer optional. Organizations that adopt AI-driven ETL as a cornerstone of their data strategies will position themselves as market leaders.
FAQs
What’s the fastest first ETL workflow to automate with AI?
The fastest ETL workflow to automate with AI involves using AI-powered tools for tasks like schema mapping, spotting anomalies, and making dynamic data transformations. These tools cut down on manual work by analyzing data sources, identifying changes in schemas, and automatically generating transformation rules. On top of that, generative AI speeds things up even more by crafting pipeline logic and infrastructure templates. This approach allows for quicker deployment and validation with very little manual effort.
How do self-healing pipelines handle schema and semantic drift safely?
Self-healing pipelines leverage AI to spot anomalies, schema changes, and data quality problems as they happen. Once detected, they automatically tweak or fix transformations to keep data accurate and prevent disruptions. This approach helps ensure that data pipelines remain reliable and operate smoothly, even when unexpected changes occur.
Which metrics prove AI-ETL is working (quality, reliability, and ROI)?
When evaluating how well AI-ETL performs, there are a few key metrics to keep an eye on. These include real-time anomaly detection, which helps spot issues as they happen, and adaptive data transformations, ensuring the system adjusts to changing data needs seamlessly.
On top of that, specific KPIs (Key Performance Indicators) provide deeper insights into its success. These include:
Automation efficiency: How well the system reduces manual effort.
Data accuracy: The reliability and precision of the processed data.
Business impact: Tangible outcomes like increased revenue or reduced costs.
Together, these metrics paint a clear picture of how well the AI-ETL process is delivering results, ensuring high-quality outcomes and measurable returns on investment (ROI).